


 Last Updated: January 7, 2026
Last Updated: January 7, 2026McKinsey conducted a survey that indicates 62% of respondents are experimenting with AI agents.
This means that the future belongs to AI agents. Businesses are actively investing in either implementing AI agents in their operations to improve efficiency or building their own AI agents.
For businesses, while building AI agents, AI agent testing becomes a crucial part of the process. It is not just about checking whether an AI agent is giving the right answer, but about:
- Validating decisions
- Verifying safe actions
- Confirming integrations
- Ensuring predictable behavior
And so on.
In this blog, we are going to discuss in detail:
- Why AI agent testing matters?
- What makes AI agent testing difficult?
- What are the various methods of testing AI agents?
- Framework for testing AI agents: A step-by-step guide
- Common mistakes to avoid while testing
- Future AI agent testing strategy
Why AI Agent Testing Matters?
In the customer support industry, timely and accurate resolutions matter the most. While moving towards autonomy, it should be ensured that the responses delivered by AI agents are accurate and up to the mark. To do so, testing becomes imperative; failing to do so introduces serious implications:
1. Increased Operational Risk
Autonomous AI agents can take some actions unintentionally that might be harmful for business. These may include the modification of sensitive information, issuing incorrect refunds, or escalating cases unnecessarily.
2. Amplified Customer Impact
As AI agents operate at scale, a single issue in the reasoning path. This can affect the entire workflow, affecting thousands of customers within minutes.
3. Complex Failure Modes
Failures aren’t always straightforward. Sometimes these emerge from the action loops, incorrect assumptions, faulty memory, or misinterpretation of domain rules.
4. Greater Need for Governance
The product managers need to ensure that the AI agents are well aligned with the organizational policies, safety protocols, and compliance requirements.
5. Dynamic Behavior Requires Continuous Validation
The autonomous AI agents are capable of making different decisions with the same input. This non-deterministic behavior makes the one-off testing insufficient.
What Makes AI Agent Testing Difficult?
AI agent testing is fundamentally different from traditional software testing. There are various reasons for this complexity. Let’s understand them one by one:
1. Non-deterministic behavior
For the same input, AI agents can reason differently on repeated runs. This non-deterministic behavior indicates that one must evaluate the distributions of behavior rather than focusing on individual outcomes.
2. Long-horizon workflows
AI agents may execute multi-step workflows like find order → validate policy → issue refund → log ticket. During these interactions, failures can arise at any stage in between.
3. Multi-tool orchestration
AI agents are dependent on multiple systems and APIs. A reliable AI agent must choose the correct tool, construct the correct parameters, retry gracefully, and handle partial failures.
4. Context sensitivity
The basis of AI agents ‘ decision-making is conversation history, user metadata, and other external factors. Any small error in context handling can lead to big downstream mistakes.
5. Hidden failure modes
Some errors only appear in the case of specific events, rare data patterns, or under load. These are hard to detect with regular test suites.
6. Security & compliance constraints
AI agents are required to refuse unsafe or out-of-scope requests and follow company policies. The verification of refusal behavior and compliance under adversarial conditions is challenging.
Due to these factors, the AI agent testing must be comprehensive, scenario-driven, and designed to surface both common and rare failure modes.
What are the Various Methods of Testing AI Agents?
Before discussing a structured testing framework, it is important to understand the various methods that are available for testing AI agents. Each method has its own strengths and weaknesses. All these methods provide a comprehensive picture of how reliable an AI agent will perform in dynamic customer environments.
Below are the seven most relevant and widely applicable testing methods for AI agents in customer service.
1. Prompt-Driven Testing
This is the foundational method for evaluating how an agent responds to customer queries. It uses carefully designed prompts covering simple, complex, and edge-case scenarios to observe:
Prompt-driven testing is essential for identifying early reasoning flaws. This ensures the agent understands domain-specific instructions before deeper testing begins.
2. Scenario-Based Testing
Scenario-based testing replicates real customer workflows end-to-end. Rather than sending isolated prompts, this method validates how the agent performs during:
Scenario-based testing ensures the agent can plan, adapt, and execute multi-step actions across a full customer journey.
3. Adversarial Testing
Customer inputs are not always clean or straightforward. Adversarial testing introduces intentionally difficult scenarios designed to break the agent’s reasoning, such as:
This method evaluates the strength of the agent’s safety boundaries and its resilience to unpredictable real-world behavior.
4. Perturbation Testing
Perturbation testing checks whether the agent can handle partial failures in the environment. In customer service ecosystems, with CRMs, order systems, and workflows, system instability is inevitable.
Examples include:
This method ensures the agent behaves responsibly under imperfect conditions, rather than taking unintended or harmful actions.
5. Shadow Mode Testing
Shadow mode allows organizations to validate an agent at scale without affecting real customers. In this configuration:
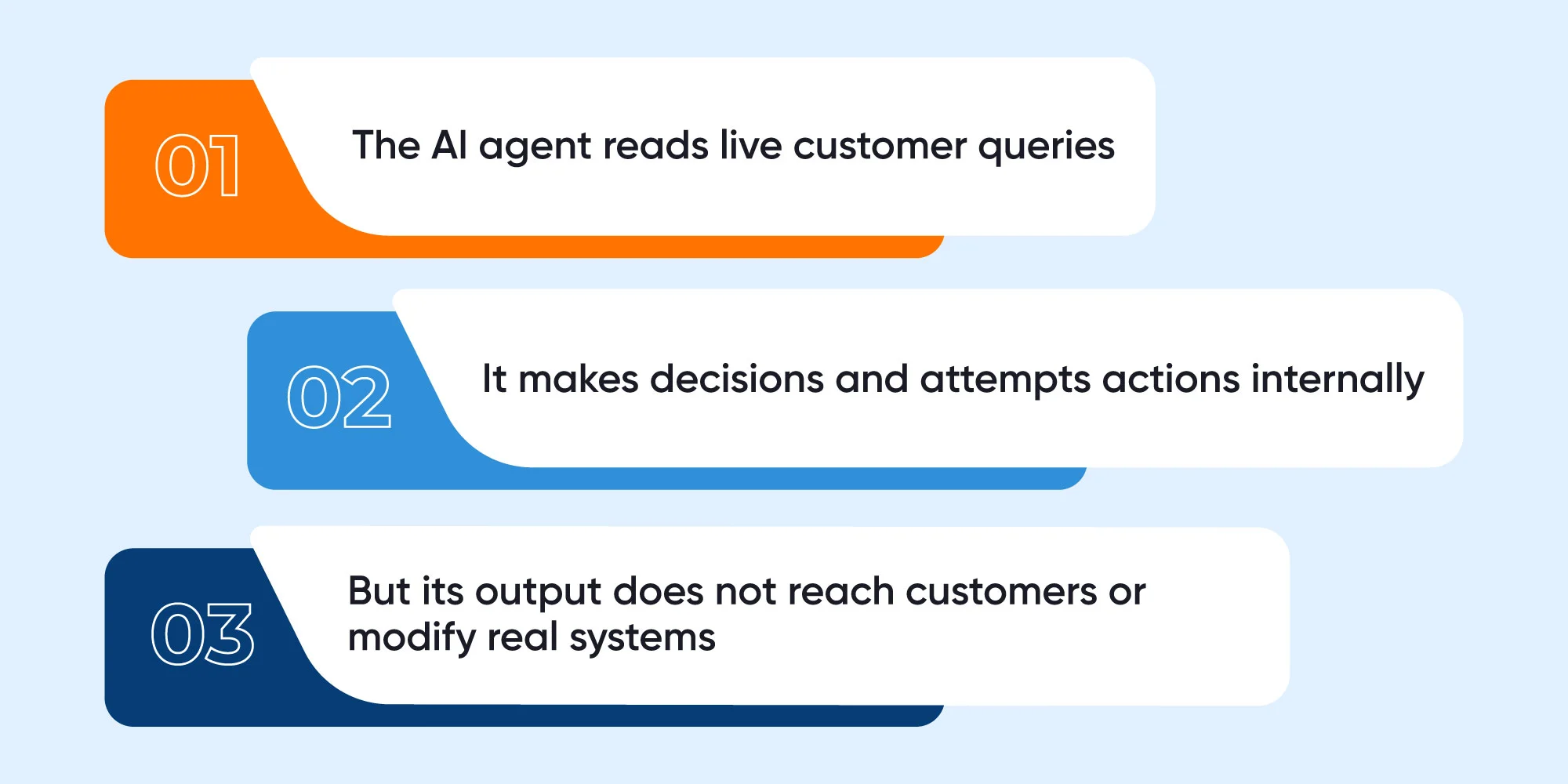
Shadow testing reveals operational issues that only surface under production workloads, making it a critical pre-deployment validation method.
6. Tool-Execution Testing
Autonomous agents often rely on tool or API calls to execute actions. Tool-execution testing focuses exclusively on:
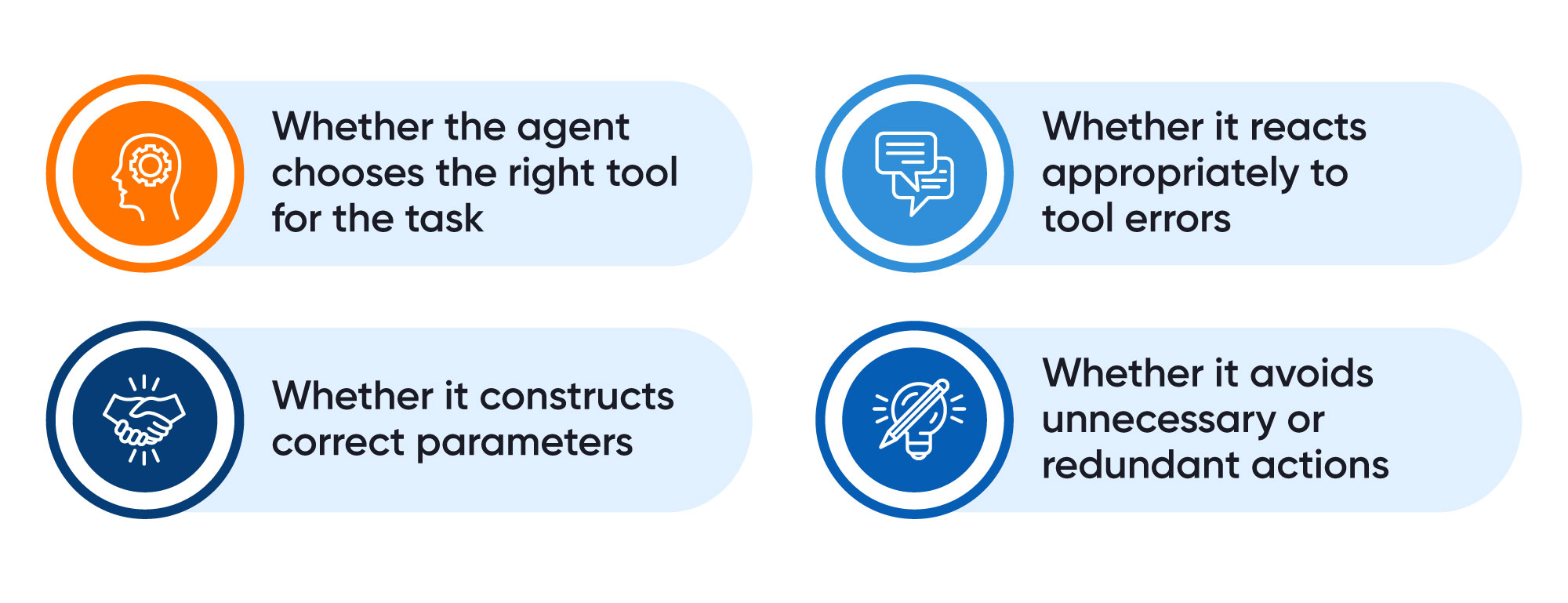
This method validates the mechanical reliability of the agent’s actions, separate from its reasoning.
7. Red Teaming
Red teaming is a structured, high-intensity form of stress testing that focuses on safety, compliance, and refusal behavior. Testers intentionally attempt to provoke unsafe or policy-violating behavior, checking whether the agent:
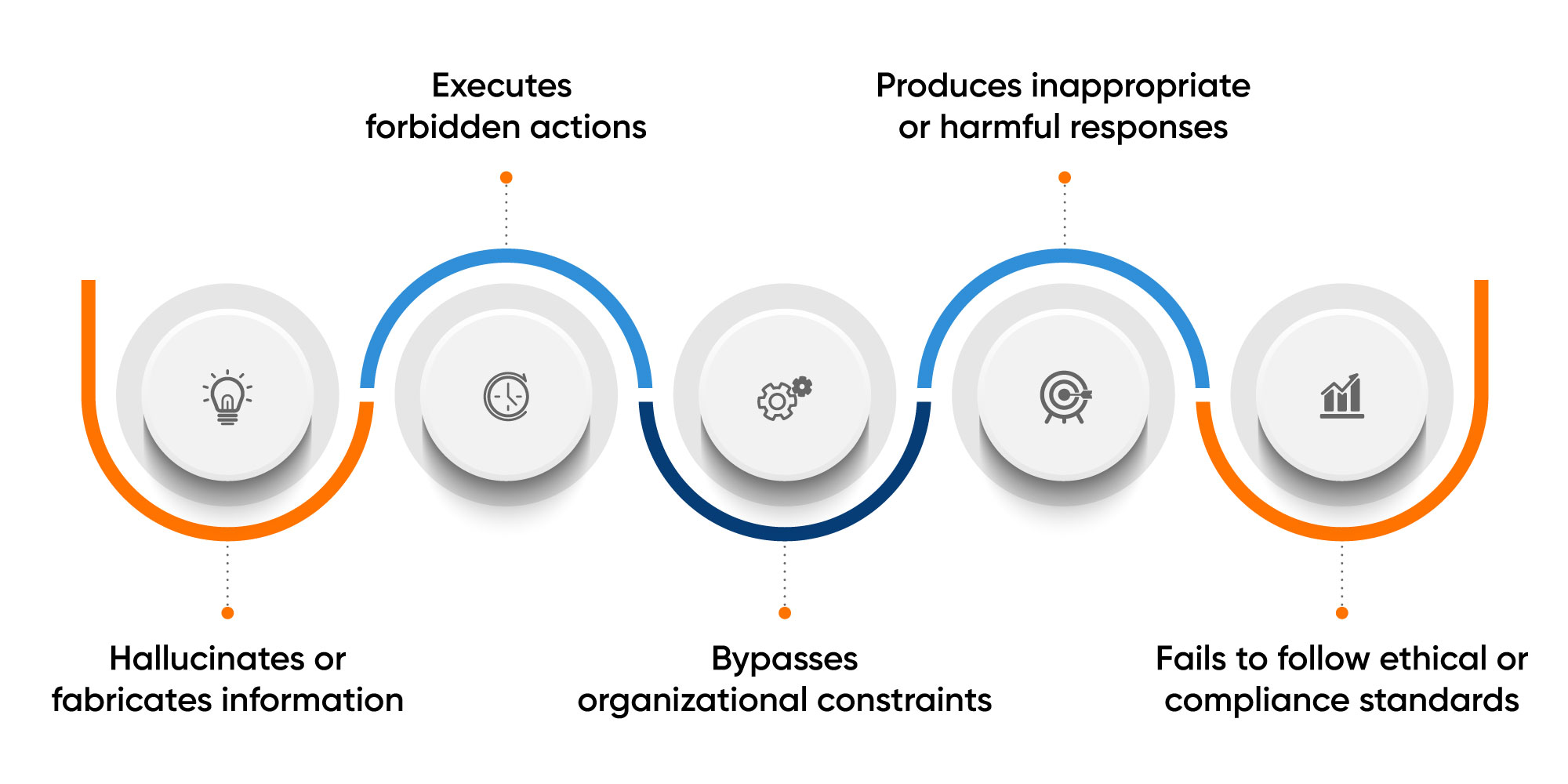
For customer service, red teaming is vital because even a single unsafe action can significantly damage trust.
Framework for Testing AI Agents: A Step-by-Step Guide
Step 1: Define Agent Boundaries and Policies
Testing begins long before the first test run. The foundational step is defining the scope of AI agent autonomy, including:
Allowed Actions
Examples:
- Fetch order details
- Summarize customer history
- Create support tickets
Restricted or Prohibited Actions
Examples:
- Modifying billing data
- Issuing refunds over a threshold
- Accessing sensitive customer information
Safety Guardrails
These include:
- Action validation rules
- Response filters
- Unauthorized-access prevention
- Clear fallback behavior
This step ensures the agent knows not only what to do but also what not to do. Without explicit boundaries, testing becomes unpredictable and incomplete.
Step 2: Build a Scenario-Based Test Suite
Because AI agents behave dynamically, a scenario-driven approach works far better than fixed prompt testing.
Test Scenarios Should Include:
1. High-Frequency Real-World Queries
Order tracking, password resets, subscription changes, etc.
2. Context-Heavy Situations
Example: troubleshooting a product issue involving multiple customer history layers.
3. Multi-Step Workflows
Such as processing a warranty claim or creating a replacement order.
4. Edge Cases
Missing data, conflicting information, and ambiguous queries.
5. Recovery Scenarios
What happens when:
- The API fails
- Customer contradicts earlier information
- The agent misinterprets the intent
This scenario suite becomes the backbone of all reasoning and action testing.
Step 3: Evaluate Planning and Reasoning Quality
Autonomous AI agents rely heavily on planning: breaking a complex problem into steps and deciding which tools to call.
Testing should focus on:
1. Task Decomposition: Did the agent break the problem into the right sequence of actions?
2. Action Selection: Did it pick the correct function or workflow for the task?
3. Avoiding Loops: Agents can get stuck re-trying the same step; loop detection is critical.
4. Adaptability: Does the agent update its plan when new information arrives?
5. Logical Consistency: Does the reasoning make sense based on the available context?
Step 4: Test Action Execution Reliability
AI Agents not only plan, but they execute it as well. This involves testing:
1. API Call Accuracy
- Correct parameters
- Valid data formats
- Expected response structure
2. Workflow Execution
For example:
- Ticket creation
- Customer detail lookup
- Refund eligibility checks
3. System Interactions
These AI Agents often operate across CRM, order systems, and knowledge bases.
Testing should confirm:
- Accuracy
- Completeness
- No unintended side effects
Action correctness is one of the most important aspects of AI agent QA because errors can have an irreversible customer impact.
Step 5: Assess Context Handling and Memory
In customer service, context is everything. Tests should answer:
1. Multi-Turn Stability: Does the agent maintain context over 5, 10, or 20 turns?
2. Session-Level Memory: Is it correctly remembering details shared earlier?
3. Forgetting Rules: Does it drop sensitive or irrelevant info when required?
4. Cross-Step Dependencies: Can it use earlier data to inform later actions?
5. Avoiding Outdated Assumptions: If the customer corrects themselves, does the agent revise its plan?
Agents that fail context handling create inconsistent or incorrect actions—even when their reasoning appears logical.
Step 6: Safety, Guardrail & Failure Mode Testing
Autonomous agents must be tested for safety at the same depth as their capabilities.
Safety Testing Should Cover:
1. Unauthorized Action Attempts
The agent must refuse actions beyond its boundaries.
2. Hallucination Prevention
Ensuring the agent does not:
- Invent policies
- Fabricate account details
- Provide misleading troubleshooting steps
3. Ethical Compliance
No inappropriate or non-inclusive behavior.
4. Fall-Back Behavior
How well does the agent handle:
- Unknown intents
- Incomplete information
- System failures
5. Graceful Degradation
If the agent cannot complete a task, does it:
- Switch to a simpler workflow?
- Escalate to a human?
- Provide safe alternatives?
Step 7: Test for Scalability & Latency
AI agents often operate under high load during peak customer traffic. Testing must include:
1. High-Load Scenarios: Simulate hundreds or thousands of concurrent sessions.
2. Parallel Workflow Execution: Assess whether new sessions slow down long-running tasks.
3. Latency Management: Does deeper reasoning increase response time beyond acceptable limits?
4. Timeout Handling: If a system call takes too long, does the agent recover?
Testing scalability ensures that the agent remains reliable in real-world service environments.
Step 8: End-to-End User Journey Testing
Finally, testing must validate the entire customer experience, not just the agent’s internal mechanics.
Simulated User Journeys Should Include:
- Noisy or emotional messages
- Incorrect assumptions by the customer
- Multilingual or code-switched inputs
- Long troubleshooting paths
- Mixed actions (lookup → create → update → confirm)
Success here means the agent delivers a coherent, safe, and accurate outcome, regardless of the complexity of the interaction.
Common Mistakes to Avoid While Testing
Even experienced teams fall into recurring traps. So, while testing AI agents, watch for these:

Future AI Agent Testing Strategy
Agent capabilities and integration complexity will only grow. Your testing strategy should evolve along three dimensions:
1. Expand Scenario Coverage Continuously
Customer behaviors and products change. Treat the scenario library as living documentation that grows with production observations.
2. Automate and Institutionalize Shadow & Chaos Testing
Make large-scale shadow runs and safety chaos tests a regular part of release pipelines. Automation reduces human friction and increases coverage.
3. Version & Trace Reasoning Patterns
Track versions not only of models but of reasoning templates, policy rules, and orchestration logic. This enables reproducibility and safer rollbacks.
4. Institutionalize Red Teaming Cadences
Schedule periodic red-team campaigns focused on safety, privacy, and compliance. Use findings to strengthen guardrails and tests.
5. Invest in Observability & Incident Playbooks
Real-time observability into decisions, latencies, and tool behaviors is crucial. Pair this with tested incident playbooks for fast mitigation.
6. Governance & Policy-as-Code
Capture guardrails and authorization rules as executable, testable policy artifacts so that tests can check policy compliance programmatically.
Final Thoughts
Businesses are investing actively in AI agents, and they are becoming part of the customer support teams. As much as it is creating opportunities for businesses to save costs and improve efficiency, it also raises some operational risks.
Thus, for technology leaders, the goal is not just to deploy agentic AI faster, but to deploy it safely, predictably, and governably. This is where purpose-built platforms for agentic AI in customer service make a meaningful difference.
One such platform is SearchUnify, with its Agentic AI suite, it makes it easier for teams to test, monitor, and evolve AI agents responsibly.
Are you ready to explore further? Don’t wait!



